Knative Practices¶
In this section, we will delve into learning Knative through several practical exercises.
case 1 - Hello World¶
apiVersion: serving.knative.dev/v1
kind: Service
metadata:
name: hello
spec:
template:
spec:
containers:
- image: m.daocloud.io/ghcr.io/knative/helloworld-go:latest
ports:
- containerPort: 8080
env:
- name: TARGET
value: "World"
You can use kubectl to check the status of a deployed application that has been automatically configured with ingress and scalers by Knative.
~ kubectl get service.serving.knative.dev/hello
NAME URL LATESTCREATED LATESTREADY READY REASON
hello http://hello.knative-serving.knative.loulan.me hello-00001 hello-00001 True
The deployed Pod YAML is as follows, consisting of two Pods: user-container and queue-proxy.
apiVersion: v1
kind: Pod
metadata:
name: hello-00003-deployment-5fcb8ccbf-7qjfk
spec:
containers:
- name: user-container
- name: queue-proxy
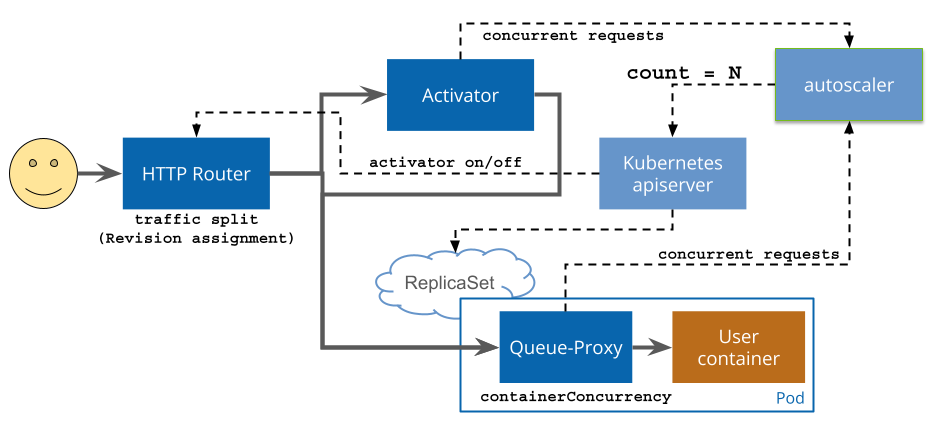
Request Flow:
- case1 When there is low traffic or no traffic, traffic will be routed to the activator.
- case2 When there is high traffic, traffic will be routed directly to the Pod only if it exceeds the target-burst-capacity.
- Configured as 0, expansion from 0 is the only scenario.
- Configured as -1, the activator will always be present in the request path.
- Configured as >0, the number of additional concurrent requests that the system can handle before triggering scaling.
-
case3 When the traffic decreases again, traffic will be routed back to the activator if the traffic is lower than current_demand + target-burst-capacity > (pods * concurrency-target).
The total number of pending requests + the number of requests that can exceed the target concurrency > the target concurrency per Pod * number of Pods.
case 2 - Based on Concurrent Elastic Scaling¶
We first apply the following YAML definition under the cluster.
apiVersion: serving.knative.dev/v1
kind: Service
metadata:
name: hello
spec:
template:
metadata:
annotations:
autoscaling.knative.dev/target: "1"
autoscaling.knative.dev/class: "kpa.autoscaling.knative.dev"
spec:
containers:
- image: m.daocloud.io/ghcr.io/knative/helloworld-go:latest
ports:
- containerPort: 8080
env:
- name: TARGET
value: "World"
Execute the following command for testing, and you can observe the scaling of the Pods by using kubectl get pods -A -w.
case 3 - Based on concurrent elastic scaling, scale out in advance to reach a specific ratio.¶
We can easily achieve this, for example, by limiting the concurrency to 10 per container. This can be implemented through autoscaling.knative.dev/target-utilization-percentage: 70, starting to scale out the Pods when 70% is reached.
apiVersion: serving.knative.dev/v1
kind: Service
metadata:
name: hello
spec:
template:
metadata:
annotations:
autoscaling.knative.dev/target: "10"
autoscaling.knative.dev/class: "kpa.autoscaling.knative.dev"
autoscaling.knative.dev/target-utilization-percentage: "70"
autoscaling.knative.dev/metric: "concurrency"
spec:
containers:
- image: m.daocloud.io/ghcr.io/knative/helloworld-go:latest
ports:
- containerPort: 8080
env:
- name: TARGET
value: "World"
case 4 - Canary Release/Traffic Percentage¶
We can control the distribution of traffic to each version through spec.traffic.
apiVersion: serving.knative.dev/v1
kind: Service
metadata:
name: hello
spec:
template:
metadata:
annotations:
autoscaling.knative.dev/target: "1"
autoscaling.knative.dev/class: "kpa.autoscaling.knative.dev"
spec:
containers:
- image: m.daocloud.io/ghcr.io/knative/helloworld-go:latest
ports:
- containerPort: 8080
env:
- name: TARGET
value: "World"
traffic:
- latestRevision: true
percent: 50
- latestRevision: false
percent: 50
revisionName: hello-00001